[논문 리뷰] Mask R-CNN (ICCV 2017)
이번에 읽게 된 논문은 Mask R-CNN 입니다.
지금 현재 Computer Vision 분야에는 주요 과제가 3가지 있습니다.
- Classification
- Object Detection / Localization
- Segmentation

출처 : https://medium.com/comet-app/review-of-deep-learning-algorithms-for-object-detection-c1f3d437b852
이번에 소개할 Mask R-CNN은 주요 과제 3가지 중 Segmentation을 수행하기 위해 고안된 모델인데요.
본격적으로 논문을 소개하기 전 Segmentation에 관하여 좀 더 자세히 알아보겠습니다.
❓Segmentaion 이란?
Segmentation은 이미지에서 pixel 단위로 객체를 추출하는 방법입니다. 이미지 내에서 개체가 있는 위치, 모양, pixel이 어떤 객체에 속하는지 등 이런 것을 알고 싶다 가정할 때, 이미지를 분할해 각 pixe마다 label을 부여합니다.
이러한 Segmentation은 여러 종류로 나뉘는데요. 대표적으로 3가지가 있습니다.
- Semantic segmentation
- Instance segmentation
- Panoptic segmentation
Mask R-CNN에서는 Panoptic segmentation를 사용하지 않게 때문에 2가지만 간단히 설명하고 넘어가겠습니다.
✅ Semantic segmentation
Semantic segmentation의 목적은 사진에 있는 모든 pixel을 해당하는 class로 분류하는 것입니다. semantic segmentation은 동일한 class의 객체는 따로 분류하지 않고, 그 pixel 자체가 어떤 class에 속하는 지만 분류합니다. 그래서 동일한 object는 같은 색으로 표현되며, 한 번에 Masking을 수행합니다. (FCN이 가장 대표적인 기법입니다.)
✅ Instance segmentation
Instance segmentation은 Semantic segmentation과 목적은 유사하지만, Semantic과 비교했을 때 각각의 같은 class의 object를 다른 label로 취급해 줍니다. 그래서 각자 객체별로 Masking을 수행하게 됩니다. (이번에 리뷰할 Mask RCNN이 대표적인 기법입니다.)

위의 그림이 instance segmentation과 semantic segmentation의 가장 큰 차이를 잘 보여줍니다.
Abstract
저자는 object instance segmentation 위한 간단하고, 유연하고 일반적인 프레임워크를 제시합니다. 이 방식은 좀더 효율적으로 객체를 감지하는 동시에 고품질 segmentation mask를 생성합니다.
Mask R-CNN은 Faster R-CNN이 확장된 방법입니다.
Introduction
Instance Segmentation은 이미지의 모든 객체를 올바르게 감지하는 동시에 각 인스턴스를 정확하게 세분화해야 하기 때문에 어렵습니다.
- Object detection : 개별 objects를 분류하고 bounding box를 사용해 각각을 위치화하는 것이 목표입니다.
- Semantic segmetation : 객체 인스턴스를 구분하지 않고 각 픽셀을 고정된 category로 분류하는 것이 목표입니다.
💡 Instance Segmentation = Object detection + Semantic segmentationObject detection과 Semantic segmetation을 결합한 것을 Instatnce Segmentation이라 할 수 있습니다.
🧐 연구 목표
Instance segmentation task에서 사용 가능한 딥러닝 프레임워크를 개발하는 것입니다.
(instance segmentation : 같은 class의 객체라도 다른 객채로 인식한다.)
Mask R-CNN
Mask R-CNN
- Stage 1 : RPN (Region Proposal Network)
- Stage 2 : in Pararell predicting the class and box offset and a binary mask for each RoI
Mask R-CNN은 위와 같은 two-stage를 사용해서 진행됩니다.


위의 이미지를 보며 Faster R-CNN과 Mask R-CNN의 모델 구조를 비교해 보겠습니다.
Faster R-CNN은 backbone을 통해 얻은 feature map을 RPN에 입력한 후 RoI를 얻습니다. 이를 RoI Pooing에 넣은 후 얻은 고정된 크기의 feature map을 fc layer에 입력합니다. 이후 Classification branch와 bounding box regression branch에 입력해 class label과 bounding box offset을 예측하게 됩니다.
Mask R-CNN은 Faster R-CNN에서 사용한 Classification branch와 bounding box regression branch에 추가로 Segmentation task를 예측하는 mask branch가 평행하게 추가된 구조입니다. 또한 RoI Pooing가 아닌 RoIAlign을 사용해 feature map을 얻습니다.
Segmentation task는 pixel 단위로 class를 분류하기 때문에 더 정교한 공간에 대한 배치 정보(spatial layout)를 필요로 합니다. 이를 위해 기존에 있던 2개의 branch들과 달리 Conv layer를 사용해 fully connected layer에 의해 output vector로 공간 정보가 붕괴되는 것을 막아 이미지 내 object에 대한 정보를 효과적으로 encoding 합니다.
<Loss Fuction>
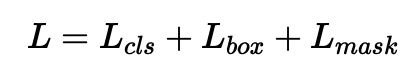
Mask R-CNN은 위와 같이 구성된 multi-task loss를 사용해 모델을 학습시킵니다. 위에 Lcls와 Lbox는 Faster R-CNN과 동일합니다. Lmask는 mask에 대한 loss로 binary cross entropy loss입니다. mask branch에서 추출한 Km^2 크기의 feature map의 각 cell에 sigmoid fuction을 적용한 후 loss를 구합니다.
RoIAlign
RoIAlign을 이해하려면 먼저 관련 배경 지식들을 이해해야 합니다.
관련 내용을 간단히 설명하겠습니다.
❓RoI 가 무엇인가?
RoI는 Region of Interest를 축약한 단어로 영상이나 이미지 내에서 관심 있는 영역입니다.
RoI를 알아보았으니 RoI Pooling에 대해 알아보겠습니다.
❓RoI Pooling이란?
Fast R-CNN의 핵심인 RoI Pooling은 RoI 영역에 해당되는 부분만 Max pooling을 통해 feature map으로부터 고정된 길이의 저차원 벡터로 축소한 단계를 의미합니다. RoI Pooling을 사용하면 입력 이미지 크기와 상관없이 고정된 feature map을 얻을 수 있다는 장점이 있습니다.
하지만 이 기존 Fast R-CNN에서 사용된 RoI Pooling에서는 quantization하게 되는데, 이 과정에서 RoI와 추측된 feature 사이에 misalignment 문제가 발생한다고 합니다. 이로 인해 이미지 속 정보가 소실됩니다. pixel 단위로 mask를 예측하는 segmentation에서는 매우 안 좋은 영향을 끼치게 됩니다.
* quantization : 입력된 실수 값을 정수와 같은 이산 수치로 제한하는 방법
그래서 저자는 misalignment를 해결하기 위해 정확한 공간의 위치를 충실히 보존하는 RoI Align이라는 단순하고 정량화가 없는 layer를 제안했습니다.
To fix the misalignment, we propose a simple, quantization-free layer, called RoIAlign, that faithfully preserves exact spatial locations. (1. Introduction)


RoI에서 얻고자 하는 정보는 박스 안의 점입니다. 위 사진에서 박스 한 칸이 1 pixel이라면 점의 좌표는 정수가 아닌 실수가 나오게 됩니다. 그러나 이미지 데이터는 정수의 값만 가지고 있으므로 bilinear interpolation(쌍선형 보간법)으로 점의 값을 구하게 됩니다.
이 과정을 통해 feature와 RoI 사이가 어긋나는 misalignment 문제를 해결할 수 있게 됩니다. 그래서 이를 통한 RoI의 정확한 spatial location을 보존하는 것이 가능해집니다.
Network Architecture
Mask R-CNN은 이미지의 feature를 추출하기 위해 ResNet과 ResNeXt의 50, 101 layer와 FPN(Feature Pyramid Network)을 backbone으로 사용하였습니다.

Figure 3. Head Architecture (왼쪽 : backbone ResNet,오른쪽 : backbone FPN)
위 그림은 Head architecture에 관한 그림입니다. 이 Head architecture는 Bounding Box Recognition(Classification and Regression)과 Mask Prediction을 위해 사용되는데요. 그림을 보시면 기존 Faster R-CNN의 Head에 Mask branch가 추가된 것을 알 수 있습니다. 추가로 backbone에 종류에 따라 Head의 구조가 달라집니다.
Experiments: Instance Segmentation
Main Results
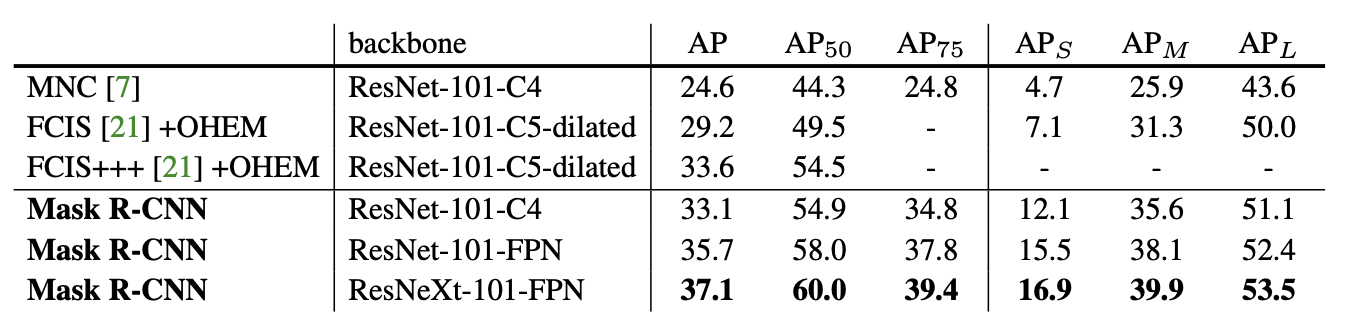

- Mask R-CNN이 state-of-the-art 모델보다 훨씬 더 우수한 성능을 보였습니다.
- ResNet-101-FPN을 BackBone으로 가지는 Mask R-CNN이 FCIS+++보다 뛰어난 성능을 보였습니다.

FCIS VS Mask R-CNN 의 결과
* FCIS : Fully Convolutional Instance-Aware Semantic Segmentation (COCO 2016 segmentation challenges 우승)
Ablation Experiments

- 네트워크의 depth가 깊을수록 성능이 좋았습니다. (a) ResNeXt-101-FPN
- Mask Branch를 분리한 sigmoid가 softmax(multinomial masks)보다 성능이 더 좋았습니다. (b) (mask branch와 classification branch를 분리)
- RoIAlign을 사용해 RoIPool, RoIWarp를 사용한 것보다 더 높은 성능을 보였습니다. (c),(d)
- Mask Branch를 할 때 MLP를 사용하는 것보다 FCN을 사용하는 것이 더 우수한 성능을 보였습니다. (e)
Bounding Box Detection Results
Mask Output은 무시하고 Mask R-CNN와 기존 object detection 모델과 결과를 비교해 보았습니다.

- ResNet-101-FPN을 사용한 Mask R-CNN이 기존의 SOTA(state-of-the-art)모델들보다 성능이 뛰어났습니다.
- Multi-task Training으로 인해 Bounding Box Detection에서도 좋은 성능을 보여주었다.
<참고자료>
Mask R-CNN (ICCV 2017) : https://openaccess.thecvf.com/content_ICCV_2017/papers/He_Mask_R-CNN_ICCV_2017_paper.pdf
https://medium.com/hyunjulie/1편-semantic-segmentation-첫걸음-4180367ec9cb
1편: Semantic Segmentation 첫걸음!
Semantic Segmentation이란? 기본적인 접근 방법은?
medium.com
https://herbwood.tistory.com/20
Mask R-CNN 논문(Mask R-CNN) 리뷰
이번 포스팅에서는 Mask R-CNN 논문(Mask R-CNN)을 읽고 리뷰해보도록 하겠습니다. Mask R-CNN은 일반적으로detection task보다는 instance segmentation task에서 주로 사용됩니다. Segmentation 논문을 읽어본..
herbwood.tistory.com
https://developpaper.com/mask-r-cnn/